TLDR: Embeddings are numerical representations of words/sentences/documents. The numerical representations are not only focused on the text's meaning but also include information about where within a larger text/document the target content is located. Embeddings are used for many AI/ML tasks focused on identifying similarities between two groups of words/sentences/documents.
What are Embeddings?
Embeddings are numerical representations of text utilized by AI/ML models. The numerical representations contain information about the text's content and its location within a larger document or set of documents. Embeddings exist within Vector Space which is used to measure the distance between two embeddings to calculate how similar they are to one another.
In the context of embeddings, a vector space is a mathematical representation where embeddings are organized in relation to each other based on their similarities and relationships.
To better understand the concept, think of a vector space as a graphing paper, where each point represents an embedding. Embeddings with similar characteristics or meanings are closer together on the paper, while embeddings with different characteristics or meanings are farther apart.
For example, an embedding at coordinates (1, 2) on the paper would be more closely related to another embedding at (2, 1) than to an embedding at (7, 1)
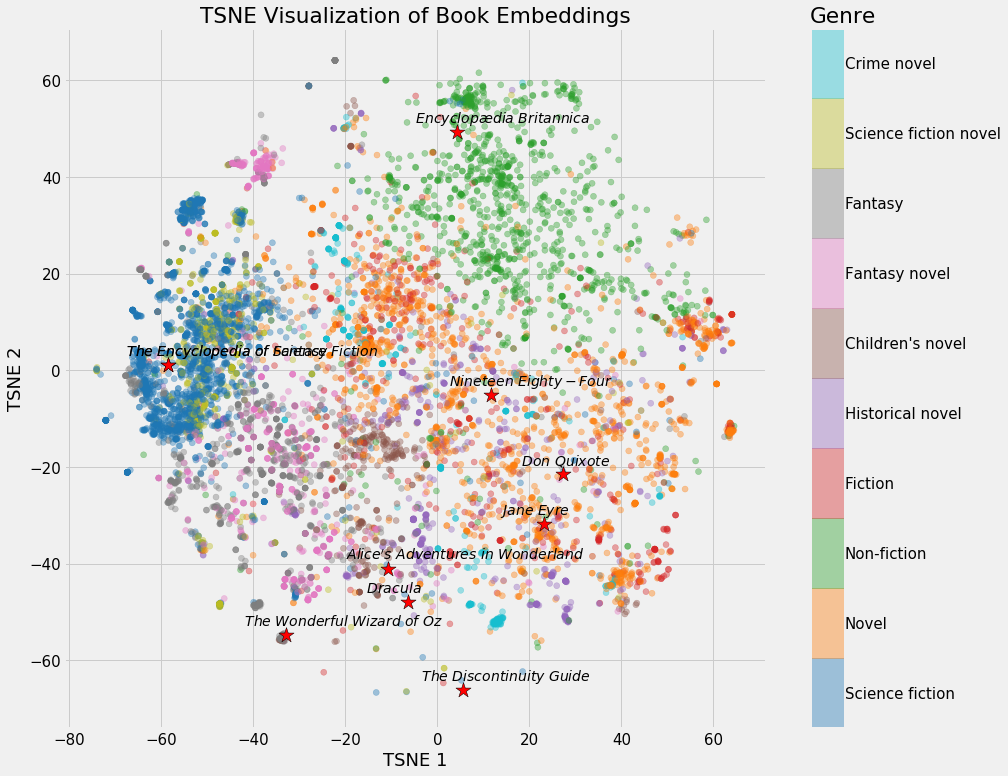
The following images provide a simple and advanced visualization of embeddings within a vector space
Embedding Types
Embeddings are divided into two main types: Word and Sentence/Document
Word Embeddings
Word embeddings focus on creating a numerical representation of a word that can be used for comparison/classification tasks.
Sentence/Document Embeddings
Sentence/document embeddings aim to generate comprehensive representations of entire sentences or documents. These embeddings consider not only the textual content but also the structure and context within which the text is located.
By assigning numerical values to these embeddings, they enable high-level summarization and support tasks such as similarity comparison, clustering, and document classification.
Word Similarity
Identifying tight relationships between words like "King" and "Queen" and loose relationships between "King" and "Kite"
Text Classification
Classify the sentiment of a document. Enabling the document to make predictions about the document's content.
Used to find similarities between a document and a sub-set of documents among a larger group of documents. This is done by comparing each document's embedding to see how similar they are.
Machine Translation
Aid in translating from one language to another by analyzing equivalent embeddings.
Named Entity Recognition
Used to classify person names, locations, or organizations in a given text.


{kind=link}